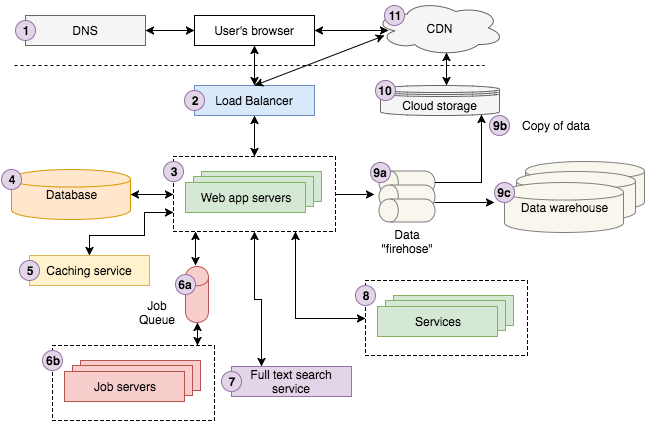
web应用基本架构
基本结构图
dns
用户发出的请求通过dns服务器,通过用户发起的域名对应到具体的应用地址,简单一点的来讲,就是一个域名和应用ip地址一个对应的键值服务
负载均衡
对应并发量很大的web应用,需要生成多个应用实例,大批量的请求来临时,通过负载均衡,就这些请求分发给不同的服务器,这些服务器应用都是一样的,可以简单理解为就是多个镜像,避免单个服务器过载
web应用
处理核心的业务逻辑,用户的请求,返回用户html代码,处理这些任务便是与后台基础设施间通信,比如数据库、缓存服务、任务队列、搜索服务、其它微服务和消息/日志队列等等。一般情况下至少两个应用服务器,或者更多,这些应用服务接入负载均衡,处理用户请求
数据库服务器
web应用都有对应的一个或者多个数据库来存储消息,一般web 应用服务器与一个数据库进行直接通信,任务服务器同理。另外,每个后台服务都有一个自己的数据库,并与其它的应用隔离(现有的分布式数据库,可以一个应用对应一个数据库集群)
- sql数据库 结构化查询语言,简单易用(大部分只支持纵向的扩展,成本很高)
- nosql数据库,用来应对大规模 web 应用中的海量数据(横向扩展非常容易)
缓存服务
缓存服务提供一种简单的键值对数据存储,使存取信息时间复杂度接近 O(1)。一般用来缓存计算成本很高的运算结果,用户经常访问的数据等
- redis
- memcache
任务队列
任务队列。它包含两部分:正在运行的任务队列,和一或多个处理任务的服务器(通常称为 workers),最简单的调度即是FIFO,现在一般应用根据自身设定的规则(调度算法)来执行任务
减少前端的响应时间,不直接影响用户的请求
全文检索服务
主要目的是为用户提供全文搜索的功能。对用户输入执行查询的时候能较快返回相近的结果(倒排索引)
通常我们会跑一个单独的“搜索服务”计算并存储倒排索引,并提供查询接口
- ElasticSearch
微服务
应用达到一定规模后,通常会拆分成单个微服务,服务之间互相通信
大数据
在应用到达一定规模时规范数据流程,ETL的过程
- 数据加工 应用响应用户交互事件,将数据发送到数据流处理平(利用kafka等消息队列来传递数据流)
- 数据存储 原始数据和转换加工后的数据在云端存储
- 数据分析 转换加工后的数据会加载入数据仓库来做后续分析(hadoop的MapReduce技术)
云存储
简单,扩展方便,用户获取更便捷。任意在本地文件系统存储的文件,你都可以通过云存储存取,并用 HTTP 协议通过 RESTful API 访问并交互。
CDN
内容分发网络,主要目的是将存储数据保存在世界各地的节点上,让不同地域的人使用该服务都能获得很好的效率